

DeepSeek V3 技术解析:AI 大模型的硬件优化新思路!
订阅
DeepSeek V3:大模型炼成的秘密武器,硬件也得跟上!
DeepSeek V3:大模型炼成的秘密武器,硬件也得跟上!
最近,DeepSeek 团队扔出了一份重磅技术报告,细聊了他们家最新的 DeepSeek-V3 模型。这份报告可不是简单的“王婆卖瓜”,而是深度剖析了训练超大规模 AI 模型时遇到的那些“坑”,以及和硬件架构相关的思考。足足 14 页的论文,浓缩了 DeepSeek 在 V3 开发过程中的经验教训,还给未来的硬件设计提供了不少灵感。厉害了,DeepSeek 的 CEO 梁文锋也参与了撰写!

V3 的独门绝技:省内存、省钱、速度快!
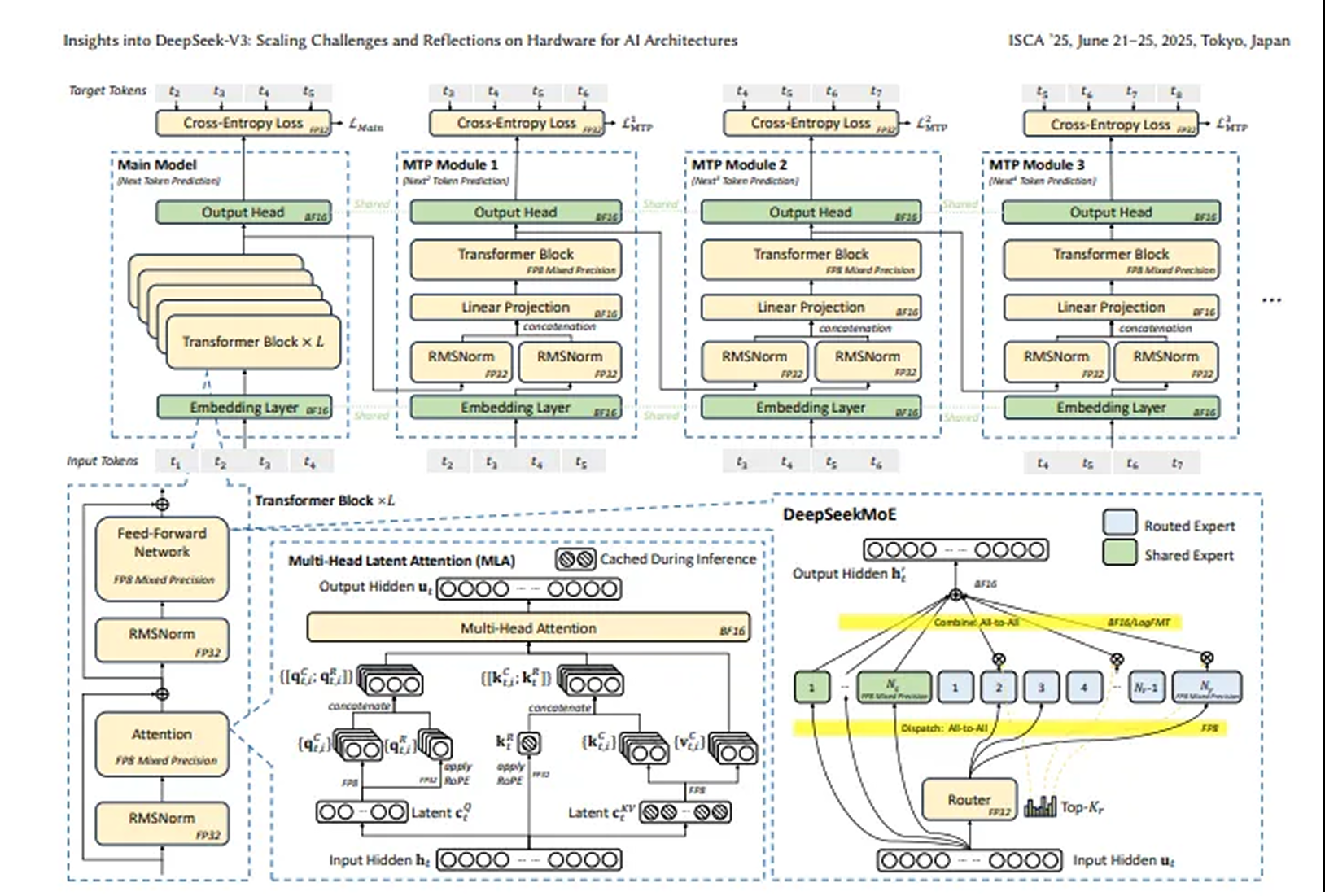
报告里提到几个关键点。首先,DeepSeek-V3 用了先进的 DeepSeekMoE 架构和多头潜在注意力(MLA)架构,内存效率直接起飞!MLA 技术通过压缩键值缓存,大幅降低了内存消耗,每个 token 只需要 70KB 内存,比其他模型省多了。
其次,DeepSeek 还抠门地进行了成本优化。通过混合专家(MoE)架构,DeepSeek-V3 激活参数的数量大幅降低,训练成本比传统密集模型最大程度地降低。而且,他们在推理速度上也下了功夫,采用双微批次重叠架构,最大化 GPU 吞吐量,保证 GPU 资源物尽其用。
未来硬件怎么搞?DeepSeek 的大胆猜想
DeepSeek 对未来的硬件设计提出了不少创新的想法。他们建议通过联合优化硬件和模型架构,来解决 LLM 的内存效率、成本效益和推理速度这三大难题。这为以后的 AI 系统开发提供了宝贵的参考。说白了,就是软硬结合,才能把 AI 的潜力发挥到极致!
阅读全文










请先 登录后发表评论 ~